Author: STWS
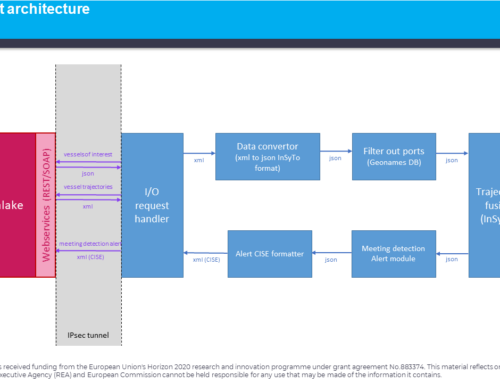
One of the main technical challenges in the project is managing the data that is ingested from various sources, because we need to make this data available to those services that need it, in the format they can read it and, in the means, they expect it. This can be classified as a hard requirement, while a soft requirement is to make managing this process in one environment, that can handle the throughput and have the ability to trace where the data is now.
The data available will move through different stages such as a flow of running water and it will be affected as it moves. An action or function will be performed on it such as:
- Ingestion – e.g., connect to AIS, read file, call web service
- Filtering – e.g., location, privacy concerns etc
- Transformation – e.g., to another data model
- Routing – e.g., send to a message bus
- Augmentation – e.g., add additional data from another source
- Storing – e.g., store the message
These functions need to be linked together in a logical flow and various technical questions arise. What happens if a function is taking to long to process the data? Does it drop the data or do we require some kind of queuing mechanism and for how long can we keep the data in this pre-function queue? This will depend on the size and the time validity of the data. A function might also need security credentials to be accessed and this needs to be taken into account that corrupt or invalid data is not injected into the flow.
Often, we tend to lean to writing our own framework but since this is an EU-funded project and we would like to leave our work to the end-user for their benefit after the close of the project, we have had to look elsewhere. Many companies and organizations and their employees have created various software which can have a broader audience and can meet other organizations requirements. This search for a suitable software framework needs to be:
- Compatible with Data Lakes
- Compatible with data sources provision methods
- Compatible with C2s
- Compatible with Analytic and Ontology services
There has been a slew of projects which have been open-sourced and made available on places such as GitHub or joined the star of open-source, The Apache Foundation. One such project which meets our needs is Apache NiFi.
Apache NiFi is an Extract, Transform and Load software project designed to automate the flow of data between systems. Based on the concepts of flow-based programming, it aims on building reliable and scalable directed graphs of data routing, transformation and system mediation logic. Through its web-based User Interface the administrator can design, control, monitor and receive feedback of the data flows. Moreover, NiFi is a highly configurable tool considering aspects of the quality of service such as loss-tolerant versus guaranteed delivery, low latency versus high throughput. Also, there is the ability to modify the flow at runtime and configure dynamic prioritization and back pressure properties. It keeps track of the data provenance from the point the data enters the flow until it reaches the destination including intermediate steps of modifying, forking and joining them.
NiFi allows its users to easily integrate their existing work and infrastructures since it supports numerous processors that allow data ingestion and connectivity from different sources. Currently, it supports around 300 native processors that perform routing, transformation, extraction and loading tasks with the ability to build and include custom components as well. Furthermore, NiFi supports the storing and loading of dataflow templates. Templates are dataflows stored in an XML file that can be exported and loaded in different NiFi instances. Thus, the best practices and solutions can be shared and benefit the collaboration and development with different partners.
Currently we are working towards implementing 31 flows and approximately 190 functions in Apache NiFi, allowing for a greater control of the data available from the end-users. This environment makes it transparent to the end-users what is happening to their data and where it is going. There are also advantages for us the technical partners who can break down work into smaller chunks and spread the responsibility and workload. We look forward to deploying the software and the processors in the trial environment and making the data available to whom requires it in a transparent manner.